
 ¿Sabes cómo utilizar archivos Robots.txt para mejorar el SEO de tu web? La gran mayoría de usuarios de Internet utiliza Google prácticamente a diario. Solo necesitan realizar una búsqueda y pueden acceder a miles de fuentes de información. Pero ¿cómo funcionan los motores de búsqueda? ¿qué tiene que ver el archivo Robots.txt con la indexación de páginas?
¿Sabes cómo utilizar archivos Robots.txt para mejorar el SEO de tu web? La gran mayoría de usuarios de Internet utiliza Google prácticamente a diario. Solo necesitan realizar una búsqueda y pueden acceder a miles de fuentes de información. Pero ¿cómo funcionan los motores de búsqueda? ¿qué tiene que ver el archivo Robots.txt con la indexación de páginas?
Aquí tienen mucho que ver la tecnología de robots de los buscadores. Ellos son los encargados de rastrear e indexar la mayor cantidad de información de las páginas web para que estén disponibles para los usuarios. Aunque esta es su principal función, los robots tienen muchas otras. Por ejemplo, los spammer las utilizan para obtener correos electrónicos rastreando las páginas de contacto de las webs.
De la misma manera, también suelen utilizarse para localizar sitios en XML o bloquear accesos a directorios o archivos de código. En cualquier caso, esta tecnología permite una mejor organización de los contenidos de Internet así como una mayor facilidad para acceder a ellos.
Si quieres que estos bots escaneen fácilmente tu web y obtengan la información que más te convenga, lo mejor que puedes hacer es utilizar los archivos Robots.txt para mejorar el SEO de tu web.
Qué es el archivo Robots.txt
Se trata básicamente de un archivo de texto sin formato que se aloja en el directorio raíz de una web. Su función principal es impedir que los robots de ciertos buscadores puedan rastrear ciertos contenidos que el webmaster no desea que sean indexados o se muestren en los resultados.
Es decir, se trata de un archivo público con la extensión .txt que le avisa a los bots rastreadores en qué partes pueden y no pueden entrar en una web. De esta manera, puedes especificar fácilmente los directorios, subdirectorios, URLs o archivos que no quieras que sean rastreados.
Pero ¿cuáles son los elementos que el archivo robots.txt es capaz de indexar o no? Resulta interesante conocer qué elementos pueden quedar recogidos en estos archivos, así como cuáles son los comandos más habitualmente usados.
Cómo funciona el archivo Robots.txt
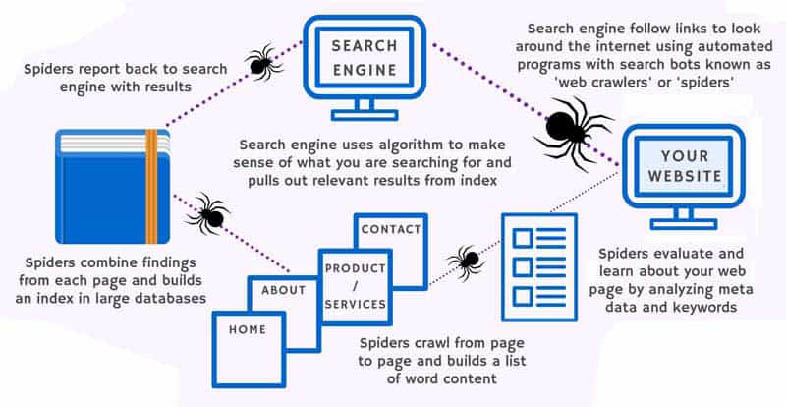 El funcionamiento de los archivos Robots.txt para mejorar el SEO de tu web es algo muy sencillo. Al crear una página web debes tener en cuenta que Google y los distintos rastreadores la examinarán en un momento dado para posicionarla.
El funcionamiento de los archivos Robots.txt para mejorar el SEO de tu web es algo muy sencillo. Al crear una página web debes tener en cuenta que Google y los distintos rastreadores la examinarán en un momento dado para posicionarla.
Por ello, es indispensable crear un archivo de texto dentro del dominio para recoger en él toda la información sobre la página que te interesa que Google sepa.
Pero es que también sirve para limitar el acceso de los rastreadores a otro tipo de informaciones. En palabras de Google: «un archivo robots.txt es un archivo que se encuentra en la raíz de un sitio e indica a qué partes no quieres que accedan los rastreadores de los motores de búsqueda».
Es decir, cuando los bots de Google se dirigen a rastrear una web, lo primero que hacen es ir al archivo Robots.txt. Después, rastrearán la página según los criterios que se hayan especificado en dicho documento de texto.
Ten en cuenta que estas instrucciones no son órdenes sino una especie de directrices. Los bots de Google pueden, en un momento dado, decidir saltarse una parte de estas directivas. Aunque lo normal es que los buscadores respeten los archivos Robots.txt.
Crear un archivo robots.txt
Para utilizar archivos Robots.txt para mejorar el SEO de tu web necesitarás acceso al directorio raíz de tu dominio. Solo tendrás que subir el archivo en formato de texto para que los buscadores comiencen a acudir a él en busca de directrices.
Sin embargo, antes habrás tenido que redactar toda una serie de directivas y comandos en dicho documento. ¿Sabes cuáles son los principales elementos que componen este archivo y para qué sirven?
1.- User-agents
El user-agent es el identificador de los robots de cada motor de búsqueda. Por ejemplo, las arañas de Google se identifican como Googlebots. De la misma manera, los robots de Yahoo se conocen como Slurp y los de Bing serían los Bingbots.
En el archivo Robots.txt se utilizan para indicar a cada user-agent un grupo de directivas. De esta manera, todas las directrices entre el primer y el segundo user-agent van dirigidas al primero de ellos. Así, las instrucciones pueden dirigirse a user-agents diferentes, o bien ser aplicados para todos.
Si deseas que todos los motores de búsqueda rastreen tu web de la misma manera, bastará con que utilices el comando «User-agent:*». Al utilizar este regla no hará falta que escribas directivas para cada uno de ellos.
2.- Directiva Disallow
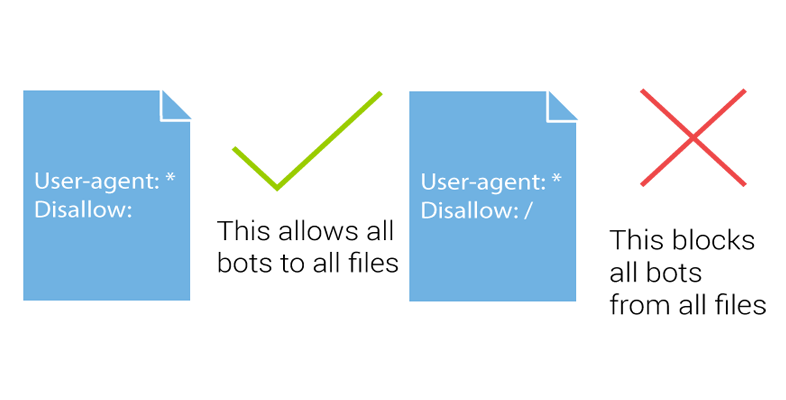 La directiva Disallow es precisamente la que se utiliza para decirle a los rastreadores que no accedan a determinada parte del contenido de la web. Para que sea tenida en cuenta debe llevar a continuación la ruta a la que no se debe acceder. Si no incluyes la ruta concreta, la directiva Disallow será ignorada y los robots accederán a todo el directorio.
La directiva Disallow es precisamente la que se utiliza para decirle a los rastreadores que no accedan a determinada parte del contenido de la web. Para que sea tenida en cuenta debe llevar a continuación la ruta a la que no se debe acceder. Si no incluyes la ruta concreta, la directiva Disallow será ignorada y los robots accederán a todo el directorio.
3.- Directiva Allow
Esta directiva es la que se utiliza para contrarrestar a la Disallow. Es decir, es una forma de decirle a los rastreadores cuando se encuentran con una ruta Disallow que pueden entrar a una parte contenido o página específica del directorio que de otra manera no estaría permitido.
4.- Sitemap
 El mapa del sitio es otro de los elementos que deberían recoger los archivos Robots.txt para mejorar el SEO de tu web. Se trata de un listado donde aparecen todas las URLs que componen el sitio, y es el primer elemento que rastrearán los motores de búsqueda al acceder para comprender la estructura de las páginas.
El mapa del sitio es otro de los elementos que deberían recoger los archivos Robots.txt para mejorar el SEO de tu web. Se trata de un listado donde aparecen todas las URLs que componen el sitio, y es el primer elemento que rastrearán los motores de búsqueda al acceder para comprender la estructura de las páginas.
5.- Crawl-delay
Esta directiva se utiliza normalmente para evitar que los servidores que tienen demasiadas solicitudes se sobrecarguen. Sin embargo, incluir el crawl-delay en el archivo Robots.txt es simplemente una solución temporal. Si tu sitio se sobrecarga normalmente es debido a un hosting de mala calidad o a una mala configuración de la página.
A pesar de ello, debes saber que crawl-delay no es compatible con Google, por lo que no te servirá de mucho incluirlo en los archivos Robots.txt para el mejorar el SEO de tu web. Para el resto de motores de búsqueda, todos lo interpretan de una forma diferente, por lo que sería necesario establecer directivas para cada uno de ellos.
Cómo pueden ayudar los archivos Robots.txt para mejorar el SEO de tu web
 Debido a su importante papel en la indexación de los sitios, los archivos Robots.txt para mejorar el SEO de tu web son muy útiles. Puedes darle instrucciones a los buscadores para indicarles la mejor manera para rastrear tu web. Y esto es algo que puedes aprovechar indiscutiblemente para mejorar el SEO de tu página.
Debido a su importante papel en la indexación de los sitios, los archivos Robots.txt para mejorar el SEO de tu web son muy útiles. Puedes darle instrucciones a los buscadores para indicarles la mejor manera para rastrear tu web. Y esto es algo que puedes aprovechar indiscutiblemente para mejorar el SEO de tu página.
La lectura de tu web se realizará de forma mucho más eficiente. Como ha quedado claro, puedes incluir directivas para evitar que los rastreadores entren en determinadas partes de tu web. Esto es una de las mejores formas de evitar el contenido duplicado, por ejemplo.
Aunque lo más recomendable es que prestes atención a este aspecto, ya que también puede provocar que determinadas páginas de tu sitio sean inaccesibles para los motores de búsqueda. Por ello, se aconseja solo bloquear el acceso a páginas que no deberían ver nunca los buscadores, entre ellas áreas de inicio de sesión con URLs diferentes o páginas de prueba.
A.- Aumenta las visitas a tu web
Utilizar archivos Robots.txt para mejorar el SEO de tu web trae como consecuencia un aumento del tráfico. Recuerda que gracias a ello estás ayudando a los motores de búsqueda a indexar tu página de forma más efectiva.
Los rastreadores recorren la web indexando todo el contenido disponible. Y estos archivos funcionan fundamentalmente con reglas de negación y restricción de acceso. La razón es que de no existir dichas directrices, los robots entienden que deben analizar todas las páginas de un sitio.
Sin embargo, puedes limitar el acceso a páginas que sean irrelevantes para tu estrategia. De esta manera, estarás ayudando a evitar que tu servidor se vea sobrepasado por los resultados de los motores de búsqueda, que al final deriva en tiempos de carga mayores o bloqueos temporales del sitio.
B.- Elimina los contenidos duplicados
Además, este protocolo de Exclusión de Robots es muy efectivo para evitar el contenido duplicado. Este último puede afectar negativamente al posicionamiento orgánico de una página. Y es que los motores de búsqueda penalizan de distintas formas:
- Filtrando el contenido duplicado para que no aparezca en resultados.
- Google penaliza automáticamente a las páginas que tienen contenido duplicado a partir del algoritmo Panda.
- Google también puede tomar medidas de forma manual revisando estos contenidos duplicados si se ha recibido una denuncia por plagio.
C.- Evita la indexación de archivos de imagen
Contar con archivos Robots.txt para mejorar el SEO de tu web también te permite controlar ciertos elementos importantes. Sobre todo, imágenes e infografías que deseas utilizar como gancho para atraer visitas.
Si evitas que estas aparezcan en resultados y tienen un gran valor informativo, es muy posible que los usuarios entren en tu página con el fin de acceder a ellas. Aunque ten presente que si estas están enlazadas directamente desde otros sitios, Robots.txt no evitará que los usuarios lleguen a través de dichos links.
En Antevenio te ayudamos a crear una estrategia de posicionamiento eficaz mejorando el posicionamiento orgánico de tu web mediante enlaces de calidad. Contacta con nosotros y pide más información.